最小二乗法と最尤法
2017.10.26

こんにちは、データサイエンスチーム tmtkです。
この記事では、回帰分析において誤差項が正規分布に従うと仮定すれば、最小二乗法が最尤法だとみなせることを説明します。
最小二乗法とは
以前の記事で説明したとおり、最小二乗法とは、回帰問題において残差の二乗和を最小化するパラメータを選択する手法です。
線形回帰について復習すると、線形回帰とは、
個のデータ
が与えられている。
- 変数
の関係が
で近似できると仮定する。
の残差
の二乗和
を最小にする
を計算する。(これが 最小二乗法 )
-
- で得られた
を用いて、データ列に
の関係があると見積もる。
- で得られた
という手続きです。
線形回帰モデル
前節では線形回帰についての概略を復習しましたが、2. の仮定の部分についてより正確に述べると、以下のようになります。
線形回帰の標準的仮定というものがあり、それは以下のとおりです。
という式が成り立つ。ここで、
は誤差項と呼ばれる確率変数である。
- 各
に対して、誤差項
である。
.
.
- 誤差項
- 説明変数
は確率変数ではない。
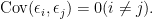
以上の仮定を標準的仮定と呼びます。(ただし、標準的仮定にはいろいろな変種があるようです。)
標準的仮定とGauss-Markovの定理
Gauss-Markovの定理という定理があります。
その内容は、以下のとおりです。
定理(Gauss-Markov)
標準的仮定のもとで、線形回帰で最小二乗法によって得られた係数
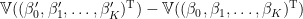
証明は省略します。
この定理から、最小二乗推定量
正規分布仮定と最尤法
線形回帰をする際、実際には上の標準的仮定にくわえて、誤差項
この仮定をくわえると、最小二乗法による推定量
いま、観測データの中にデータ

です。したがって、残差に関する尤度関数は
です。対数尤度関数は、
です。この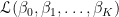
また、議論を振り返ると、最小二乗法で与えるパラメータが最尤推定量であることを示すためには、回帰問題が線形回帰であることは使っていません。回帰する関数がなんであろうと、誤差項が平均0の正規分布に従うとき、最小二乗法が有効だといえると思います。


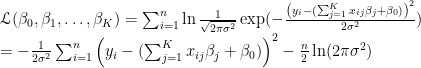
まとめ
- 標準的仮定から、最小二乗法で求めたパラメータが最良線形不偏推定量であることを導けます。(Gauss-Markovの定理)
- さらに誤差項が互いに独立であることと正規分布に従うということを仮定すれば、最小二乗法で求めたパラメータが最尤推定量であることが導けます。
- 誤差項が正規分布にしたがうと仮定したときの回帰問題では、最小二乗法が有効です。
参考
- 倉田博史・星野崇宏『入門統計解析』新世社,2009年
- Gauss–Markov theorem – Wikipeida
- Gauss-Markov Theorem, Weighted Least Squares(PDF)
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。
Recommends
こちらもおすすめ
-

スペクトラルクラスタリング入門
2017.11.2
-

統計でデータを活用!Japan Rに参加して
2017.12.3
-

GoogleのCloud Vision APIの文字認識を試す
2018.11.9
-

統計的仮説検定とは?サンプルサイズの決め方も解説
2018.5.18
-

機械学習を学ぶための準備 その3(行列について)
2015.12.6

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15